Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Instituto Superior Técnico, September 2014 – July 2017
Final Grade Average: 18.00 / 20
Awarded three academic excellence diplomas (one for each academic year)
Imperial College London, October 2017 – October 2018
Modules: 68.2/100 (Merit)
Individual Research Project (Master’s thesis): 75/100 (Distinction)
Imperial College London, October 2019 – July 2023
Working on generative modeling and self-supervised learning on audio-visual speech.
Imperial College London, February 2019 – October 2019
Worked as a research assistant in the Intelligent Behaviour Understanding Group (IBUG) at Imperial College London, supervised by Maja Pantic and Björn Schuller. Developed research projects on video-to-speech synthesis and audio-visual self-supervised learning.
Imperial College London, January 2020 – April 2020
Worked as a teaching assistant for the Introduction to Machine Learning (70050) course, led by Dr. Josiah Wang at Imperial College London.
Meta, August 2021 – December 2021
Developed a collaboration between my team at Meta (led by Maja Pantic) and another team at Meta Reality Labs Audio Research (led by Vamsi Krishna Ithapu), which was focused on audio-visual speech enhancement.
Meta, March 2022 – June 2022
Continued my work in audio-visual speech enhancement from the previous internship, and developed new collaborations with other researchers.
Meta, June 2022 – September 2022
Continued my work in audio-visual speech enhancement from the previous internship, resulting in a new research paper: LA-VocE: Low-SNR Audio-visual Speech Enhancement using Neural Vocoders.
Sony, September 2023 – November 2023
Developed a novel video-to-audio synthesis model, establishing a colaboration between two teams at Sony R&D.
Meta, November 2023 – June 2025
Developing new audio-visual speech models. My main project has been Automated Dubbing for Instagrams Reels. I have also written papers on audio-visual speech enhancement (Interspeech 2024), speech extraction (ICASSP 2025), speech recognition (NeurIPS 2024), and facial animation (CVPR 2025 + under review + under review).
Google DeepMind, July 2025 – Current
Working on something new.
Interartes, August 2010 – September 2015
Took classes at Interartes and played with a Jazz band for 4 years, frequently in front of live audiences. During this time I was also taught the fundamentals of Music Theory and Harmony.
Instituto Superior Técnico, February 2016 – July 2017
Was a member of the Computer Software Security group (STT) representing Instituto Superior Técnico and led by professor Pedro Adão, where I frequently engaged in CTF (Capture the Flag) to score points for our team.
Meta, March 2022 – September 2022
Organized a Jazz band with my team at Meta named Landmarks, where I played bass every week.
Imperial College London, March 2022 – June 2023
Attended and presented in a bi-weekly research group with some of my colleagues from Imperial College London. We usually focus on deep learning applied to speech and audio. Some of my presentations (including slides) are available in the Talks section.
Imperial College London, January 2022 – June 2025
Organize a squash club with weekly matches.
Published:
I started my own academic Twitter account where I regularly publish updates on my research.
Published:
Posted on r/machinelearning about my experience with ResNets, and my lack of success with other recent vision models such as EfficientNet.
[post]
Published:
Gave an interview for VICE, conducted by Todd Feathers, where I discussed the field of lip reading and our role as AI researchers at Imperial College London.
[article]
Pingchuan Ma and Rodrigo Mira (equal contribution), Stavros Petridis, Björn W. Schuller, Maja Pantic
Published in Interspeech, 2021
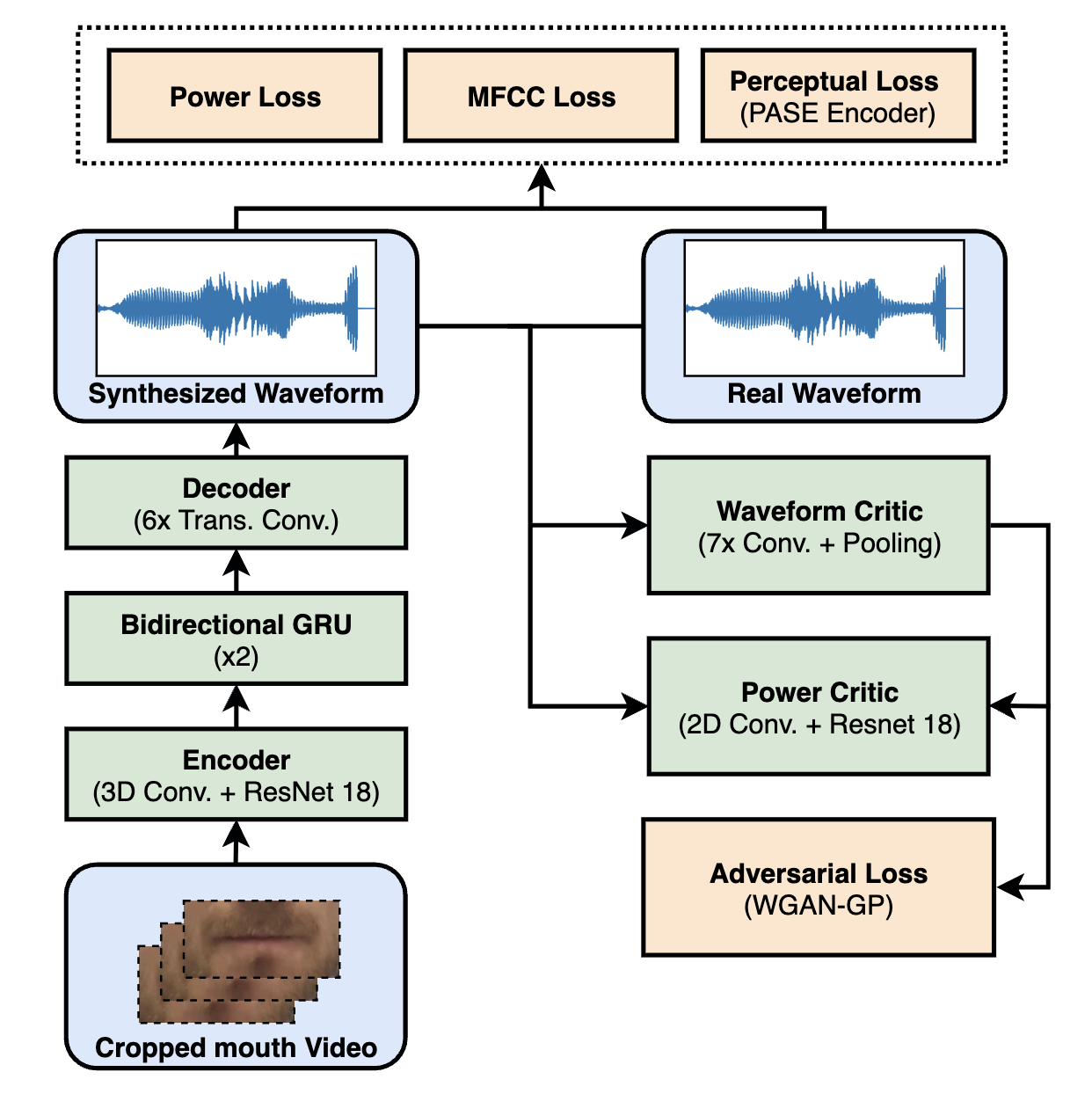
Rodrigo Mira, Konstantinos Vougioukas, Pingchuan Ma, Stavros Petridis, Björn W Schuller, Maja Pantic
Published in IEEE Transactions on Cybernetics, 2022
[project page] [paper] [bib]
Alexandros Haliassos, Rodrigo Mira, Stavros Petridis, Maja Pantic
Published in CVPR, 2022
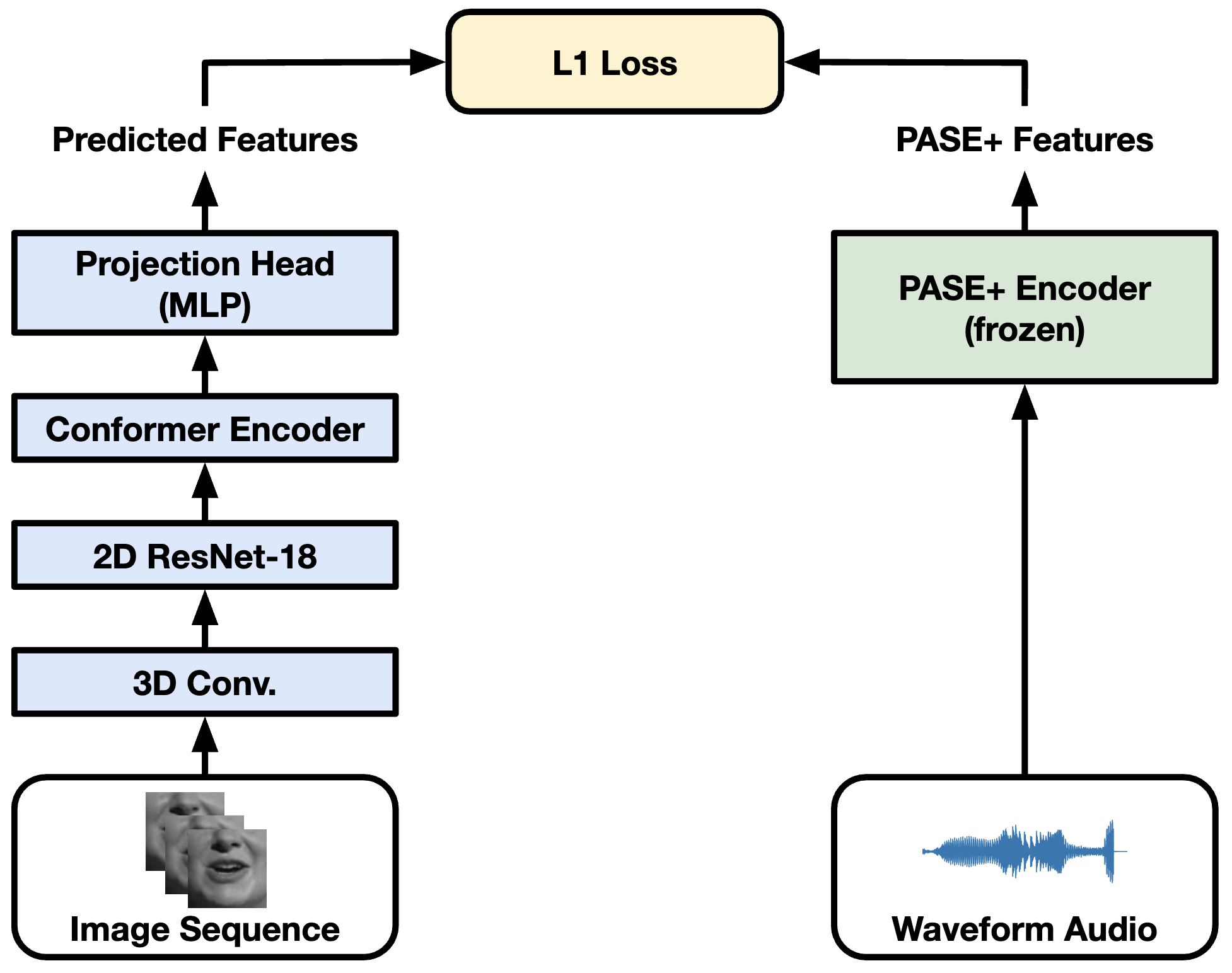
Rodrigo Mira, Alexandros Haliassos, Stavros Petridis, Björn W Schuller, Maja Pantic
Published in Interspeech, 2022
[project page] [paper] [bib]
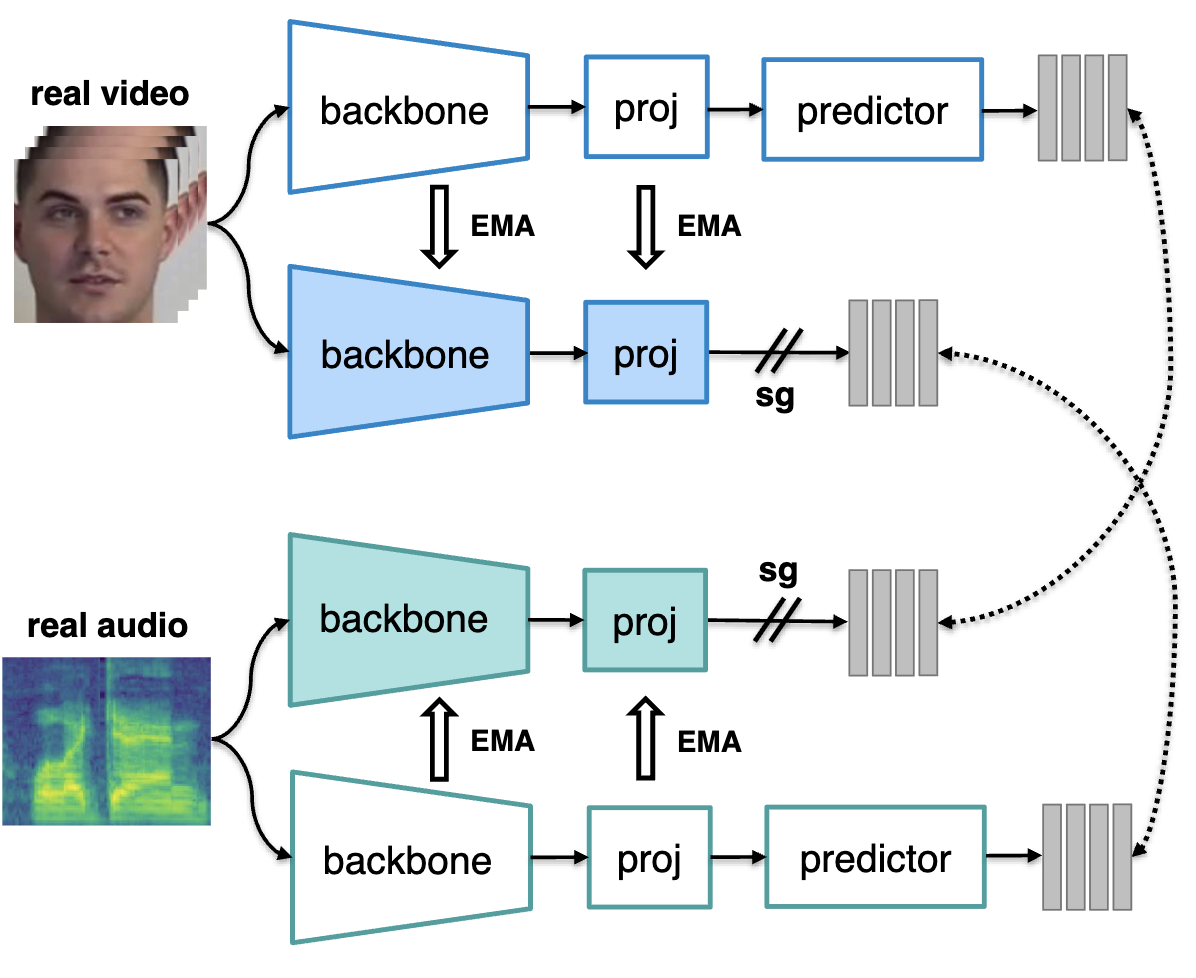
Alexandros Haliassos, Pingchuan Ma, Rodrigo Mira, Stavros Petridis, Maja Pantic
Published in ICLR, 2023
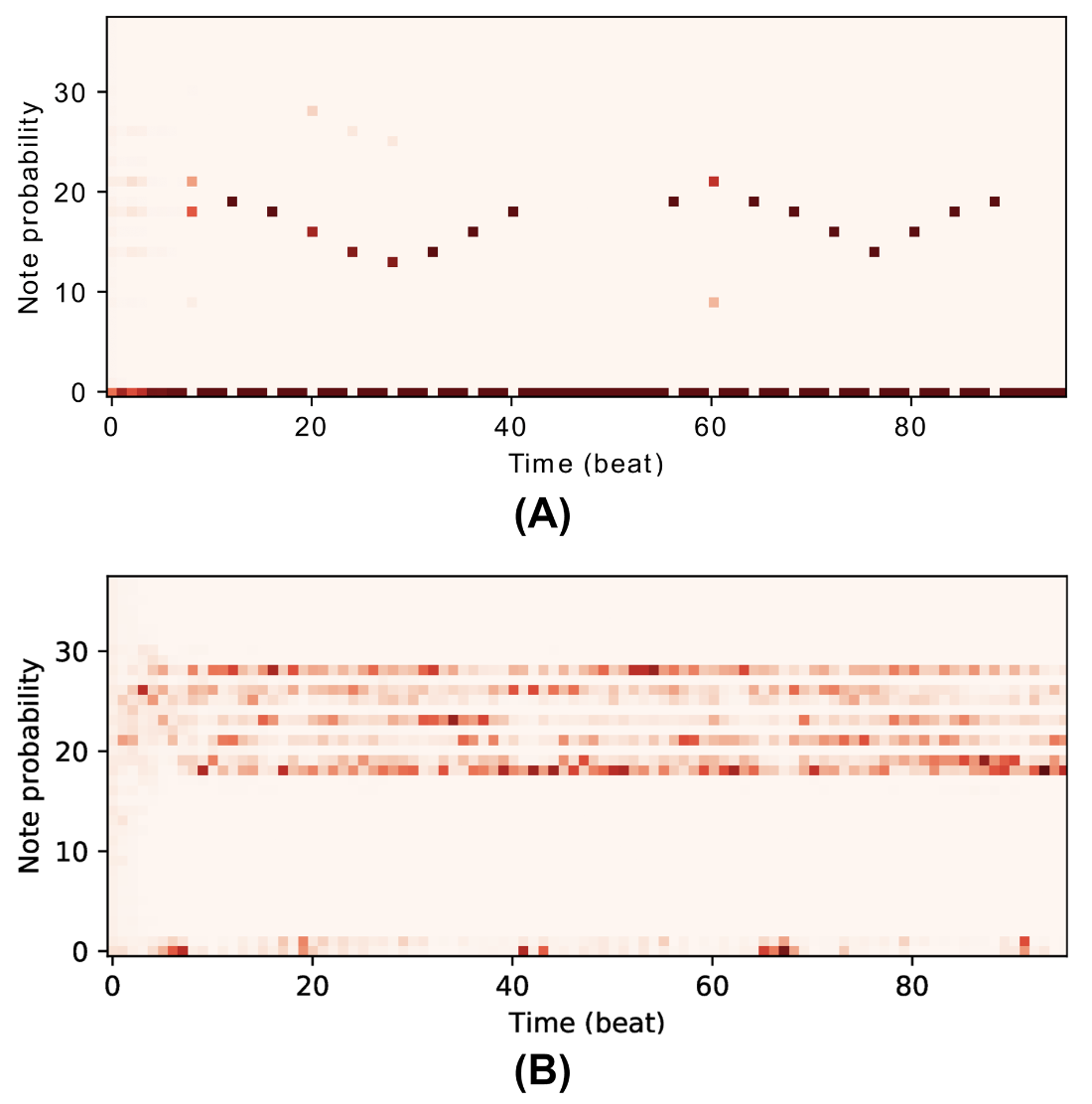
Rodrigo Mira, Eduardo Coutinho, Emilia Parada-Cabaleiro, Björn W Schuller
Published in PeerJ Computer Science, 2023
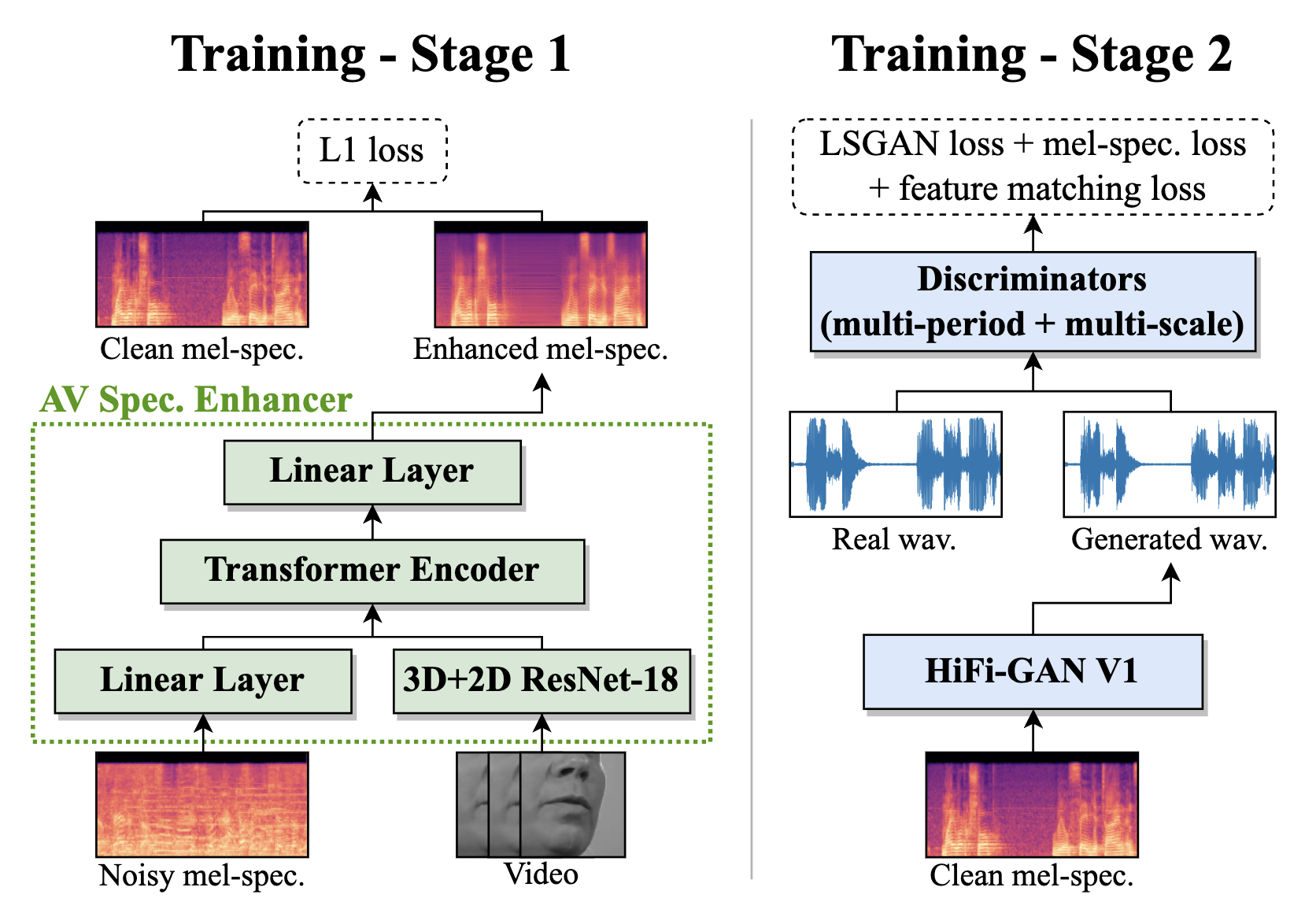
Rodrigo Mira, Buye Xu, Jacob Donley, Anurag Kumar, Stavros Petridis, Vamsi Krishna Ithapu, Maja Pantic
Published in ICASSP, 2023
[project page] [paper] [bib]
Antoni Bigata Casademunt, Rodrigo Mira, Nikita Drobyshev, Konstantinos Vougioukas, Stavros Petridis, Maja Pantic
Published in BMVC, 2023
[project page] [paper] [code] [bib]
Alexandros Haliassos and Andreas Zinonos (equal contribution), Rodrigo Mira, Stavros Petridis, Maja Pantic
Published in ICASSP, 2024
Honglie Chen and Rodrigo Mira (equal contribution), Stavros Petridis, Maja Pantic
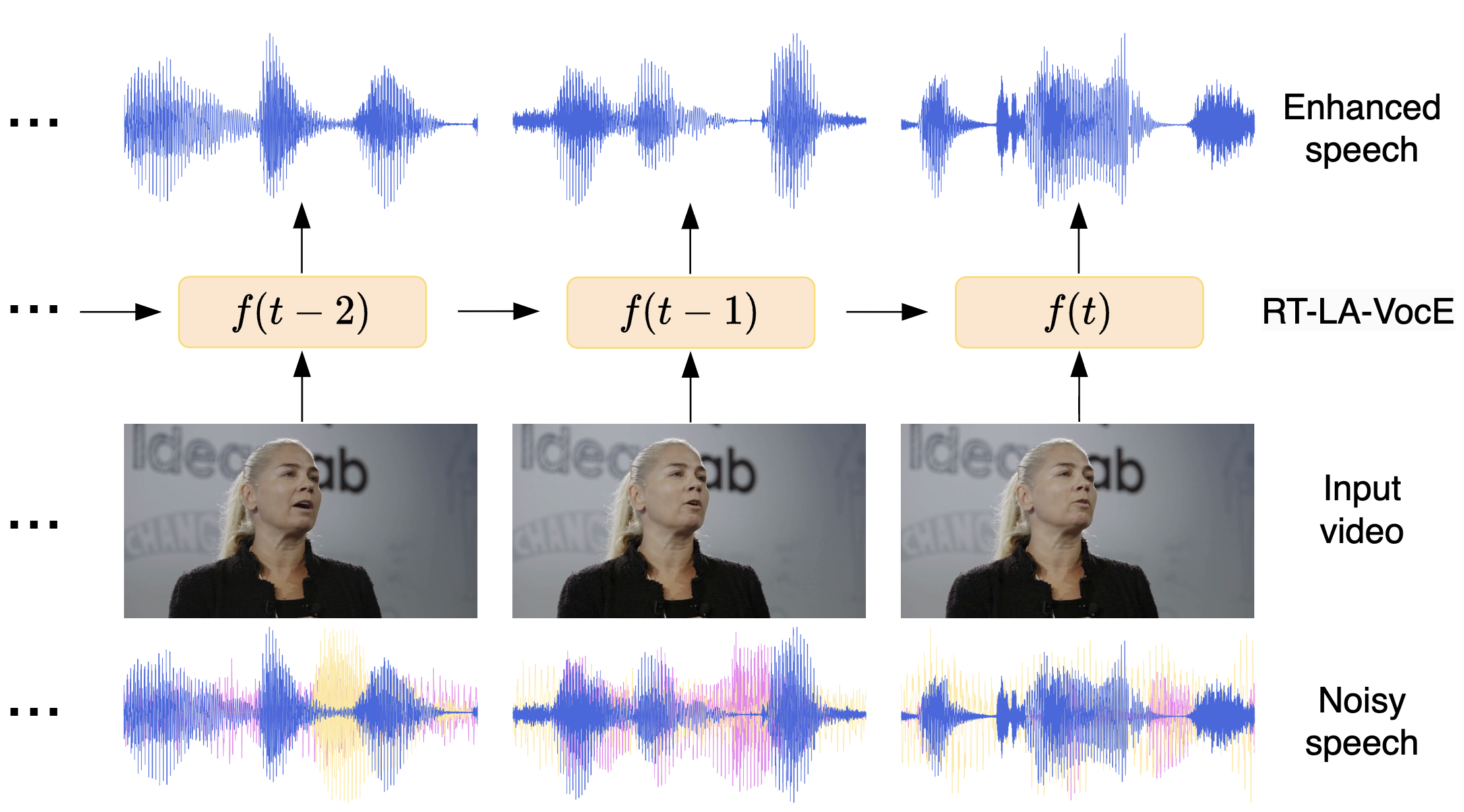
Published in Interspeech, 2024
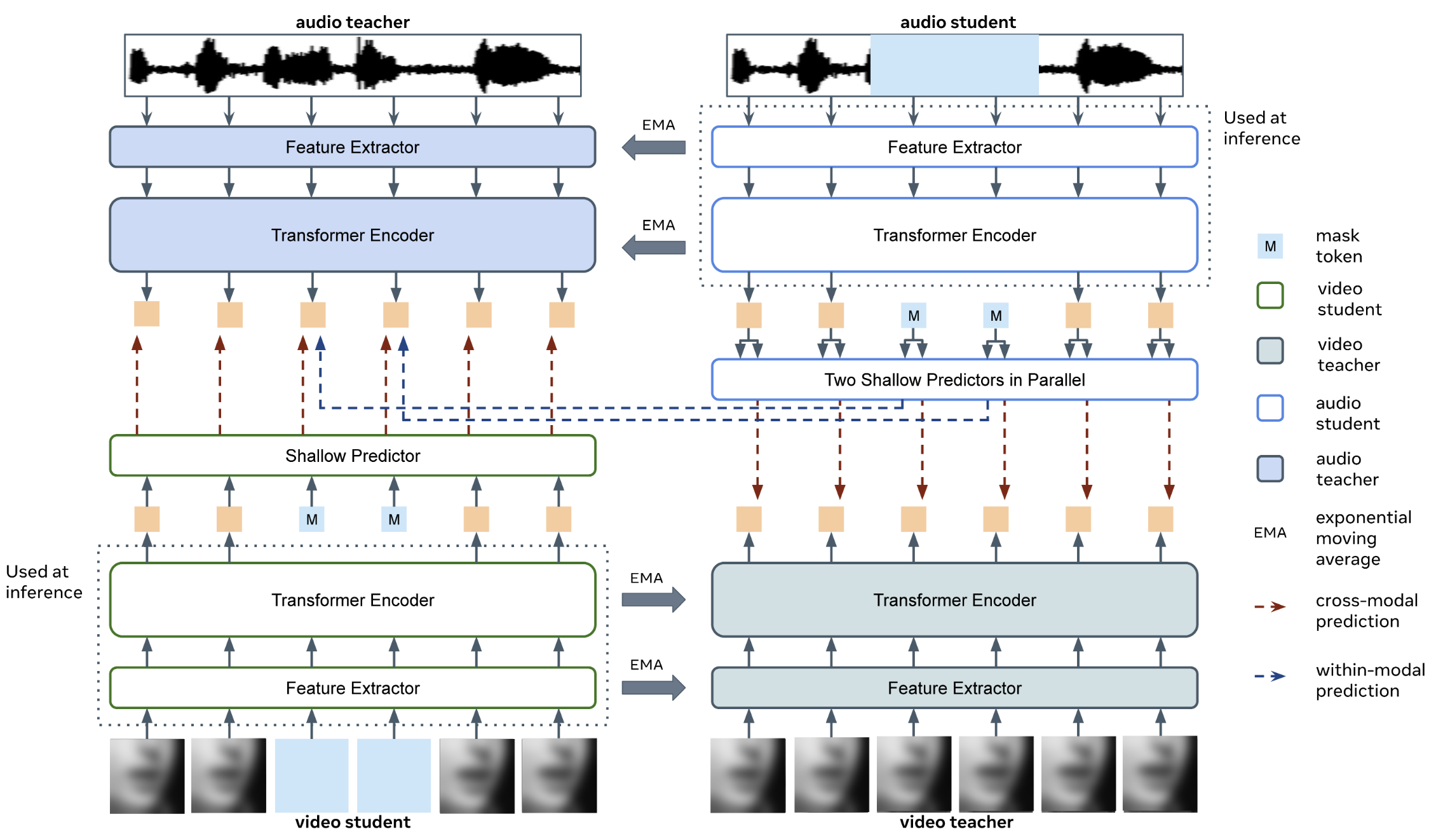
Alexandros Haliassos, Rodrigo Mira, Honglie Chen, Zoe Landgraf, Stavros Petridis, Maja Pantic
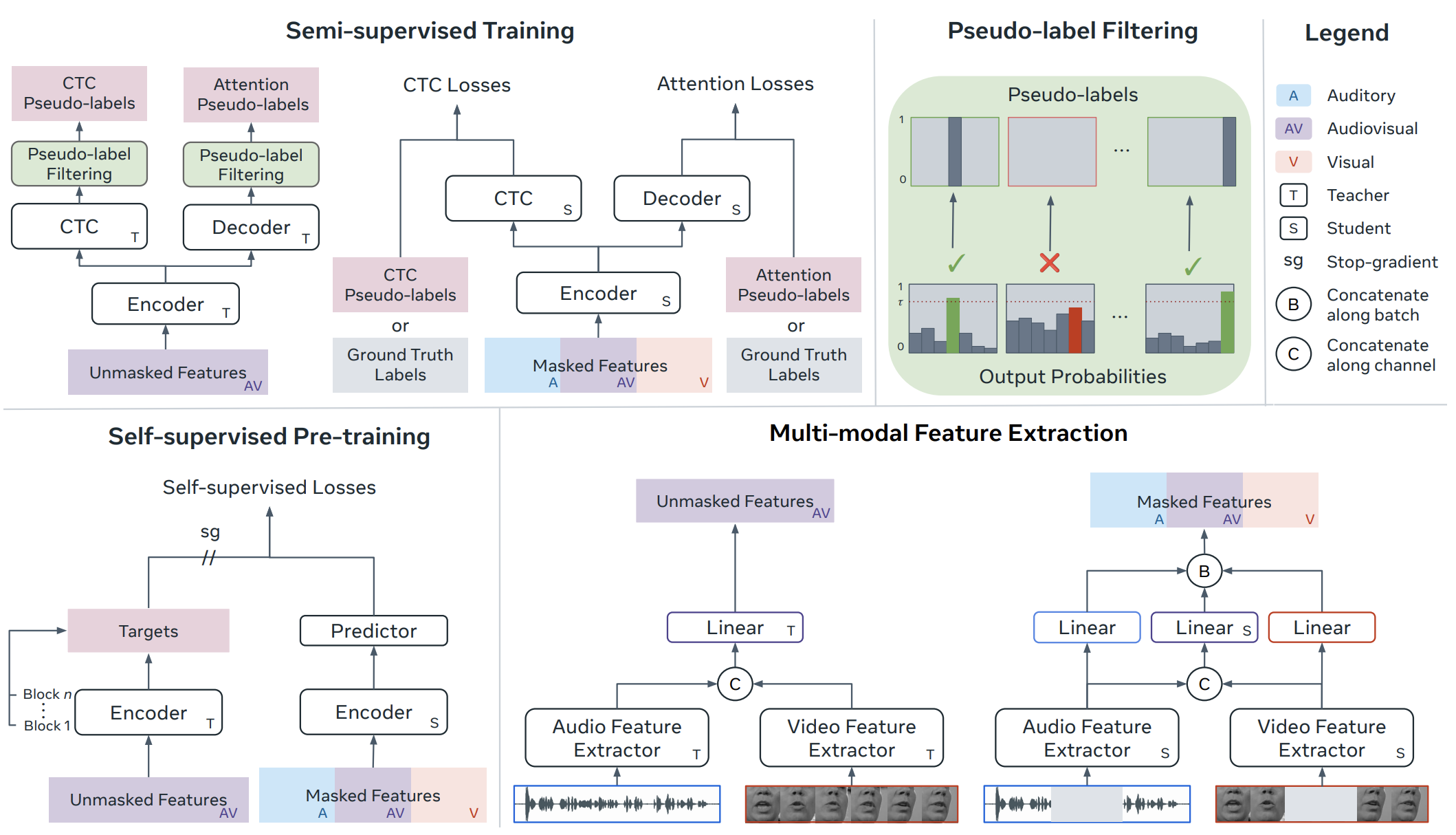
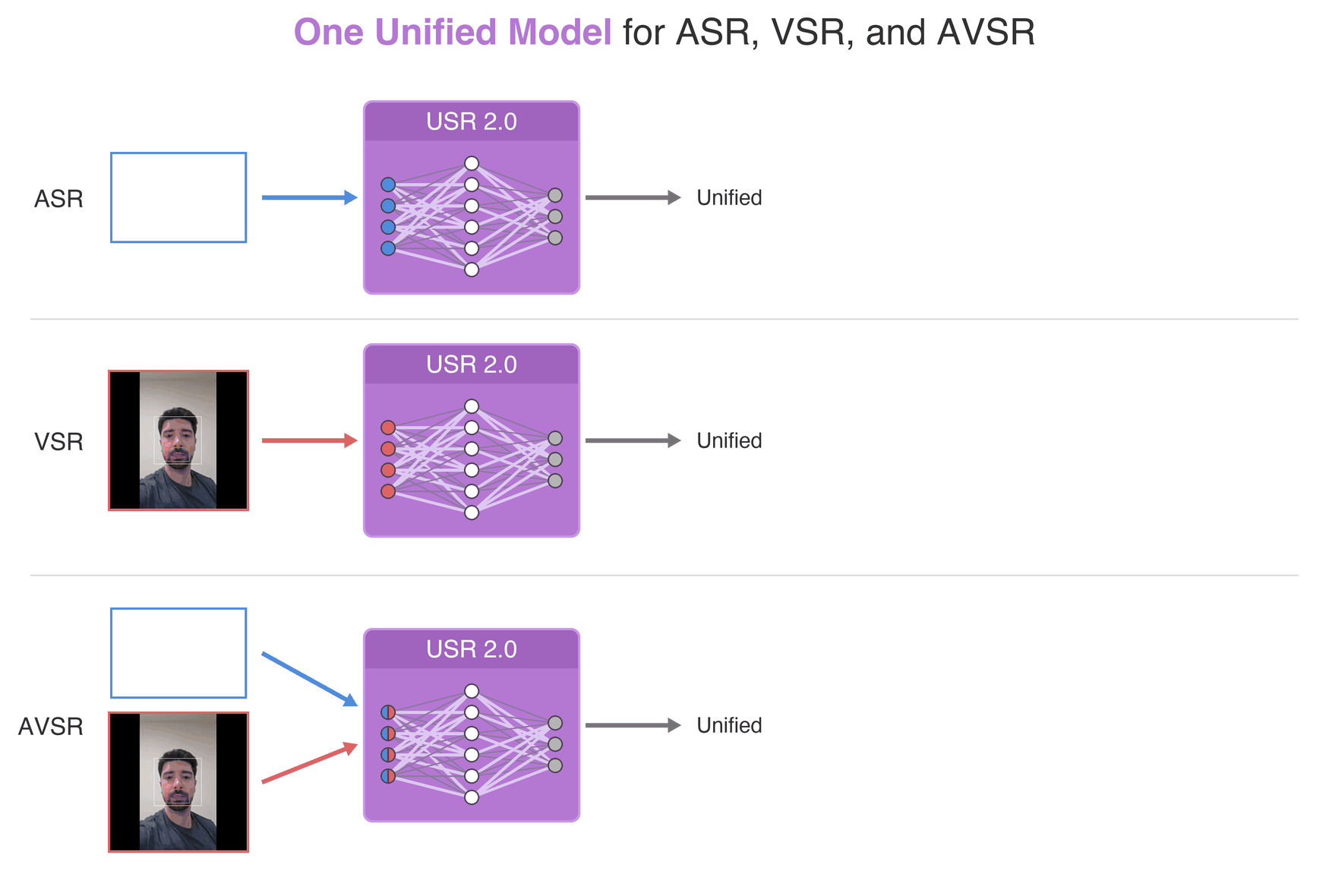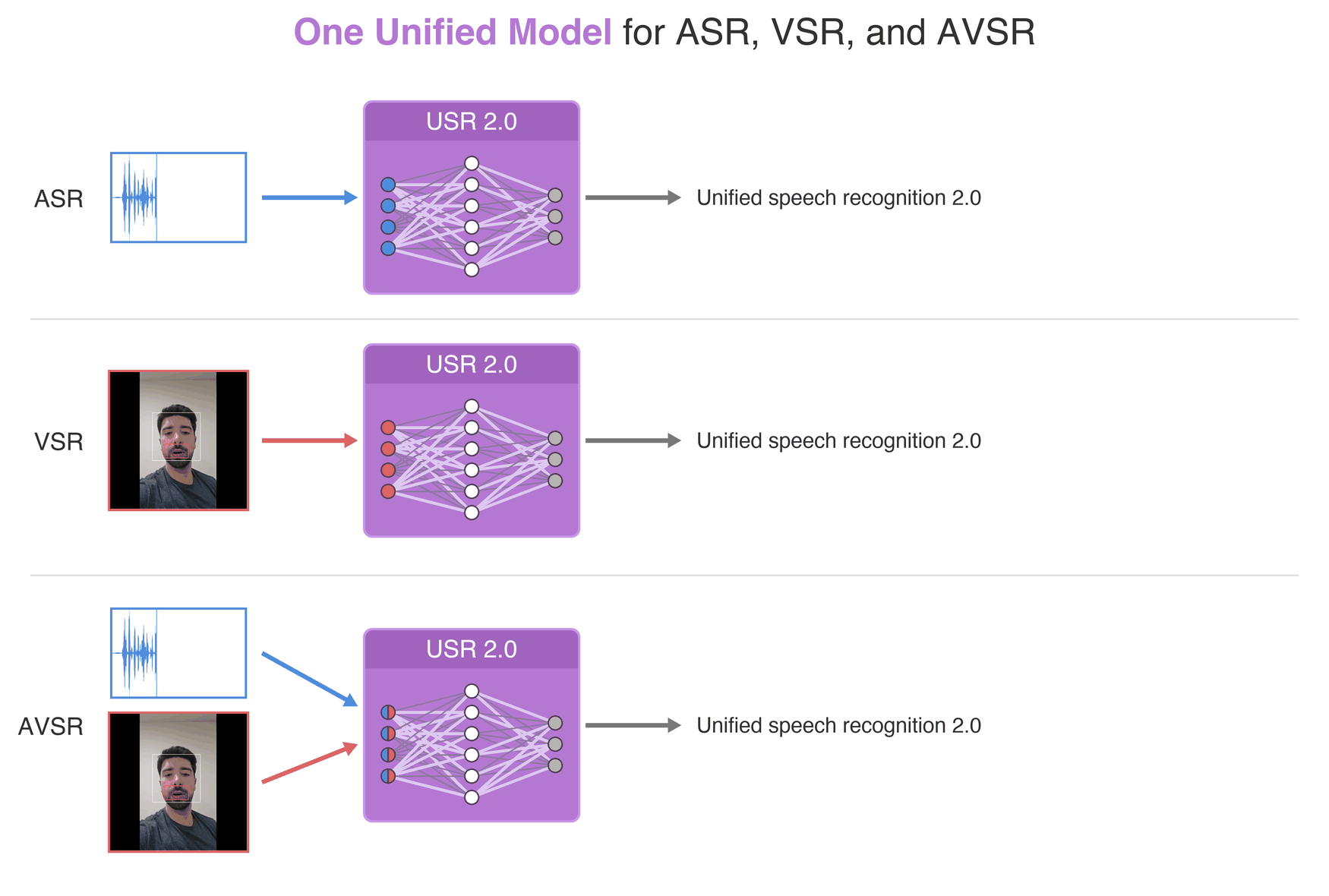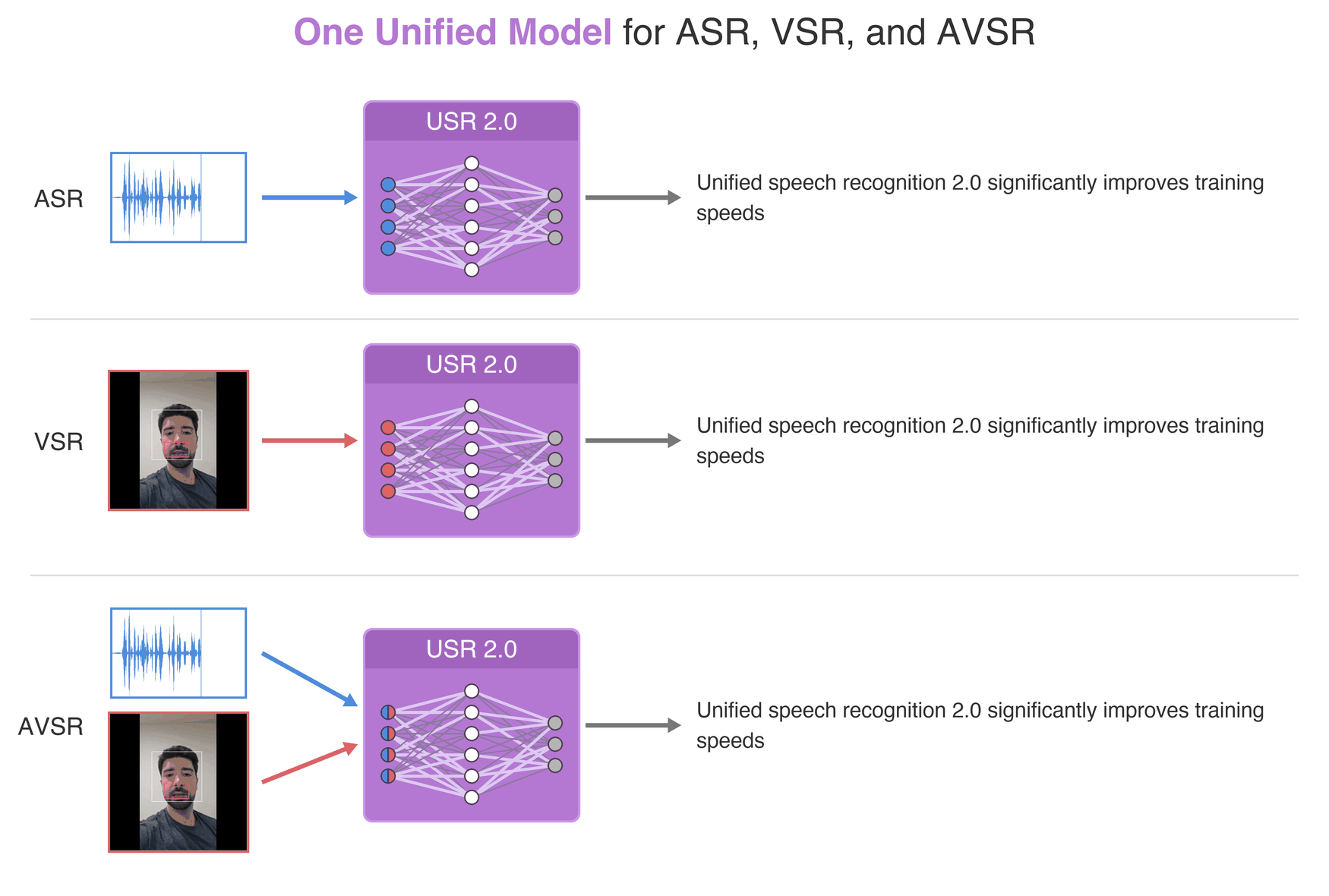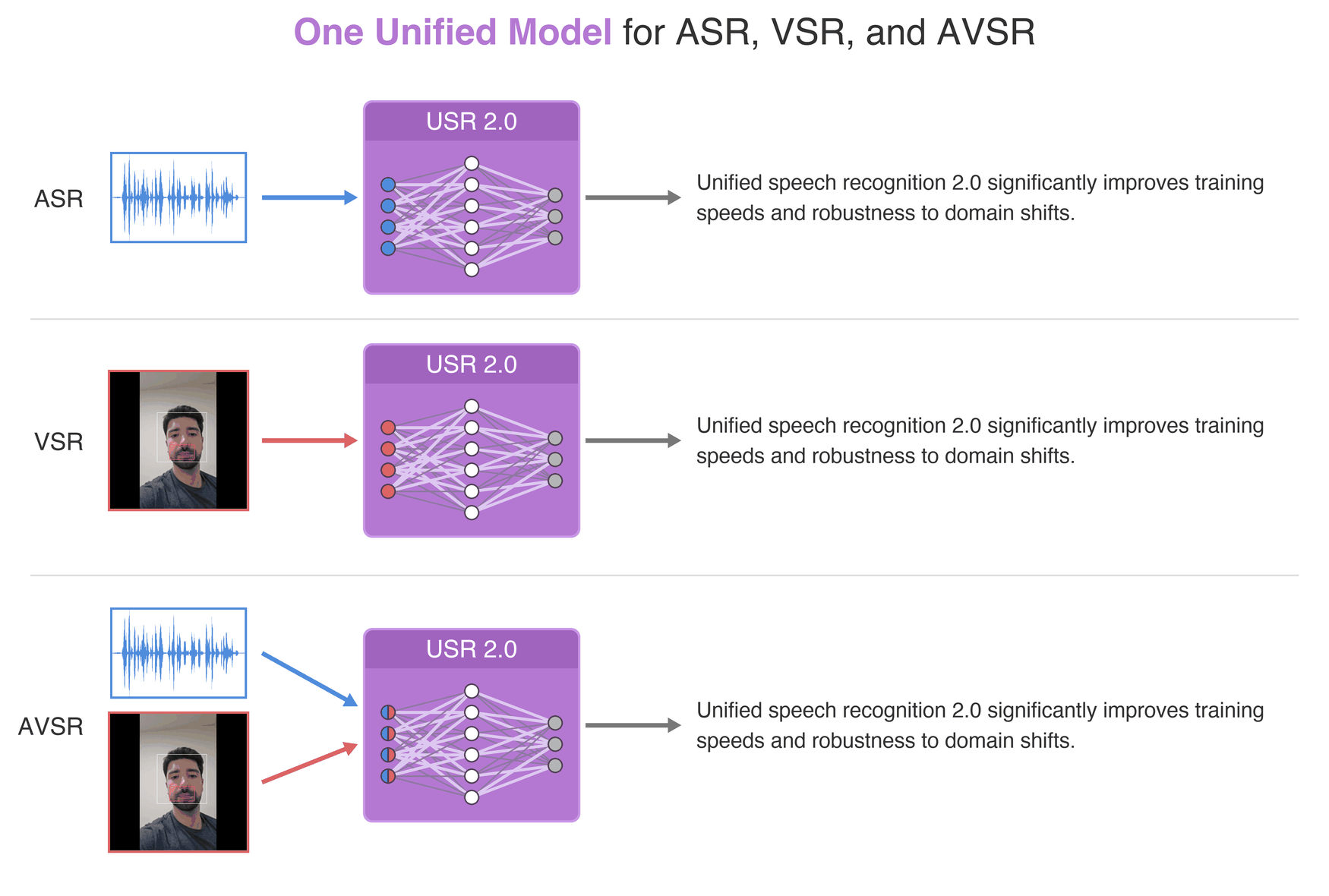
Published in NeurIPS, 2024
[paper] [code] [presentation by Alex] [bib]
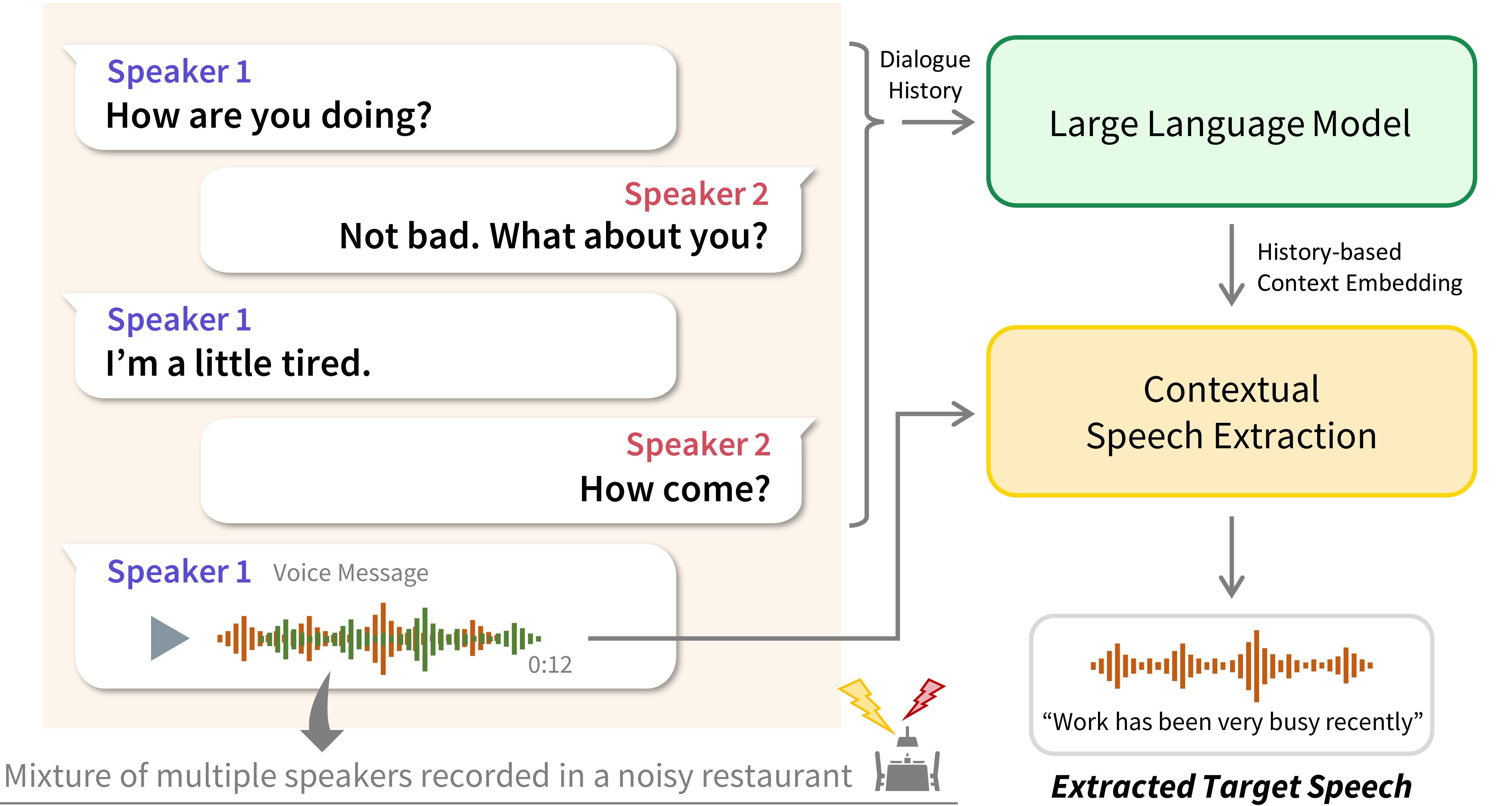
Minsu Kim and Rodrigo Mira (equal contribution), Honglie Chen, Stavros Petridis, Maja Pantic
Published in ICASSP, 2025
[paper] [project page] [code] [presentation] [bib]
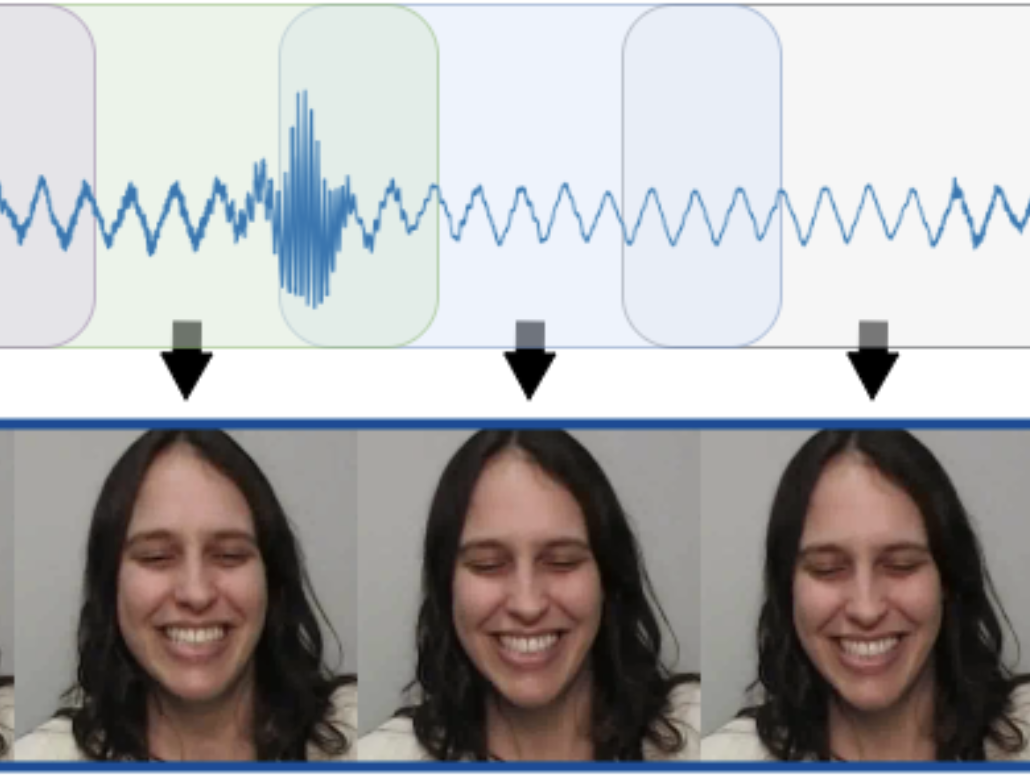
Antoni Bigata, Michał Stypułkowski, Rodrigo Mira, Stella Bounareli, Konstantinos Vougioukas, Zoe Landgraf, Nikita Drobyshev, Maciej Zieba, Stavros Petridis, Maja Pantic
Published in CVPR, 2025
[paper] [project page] [code] [presentation by Antoni] [bib]
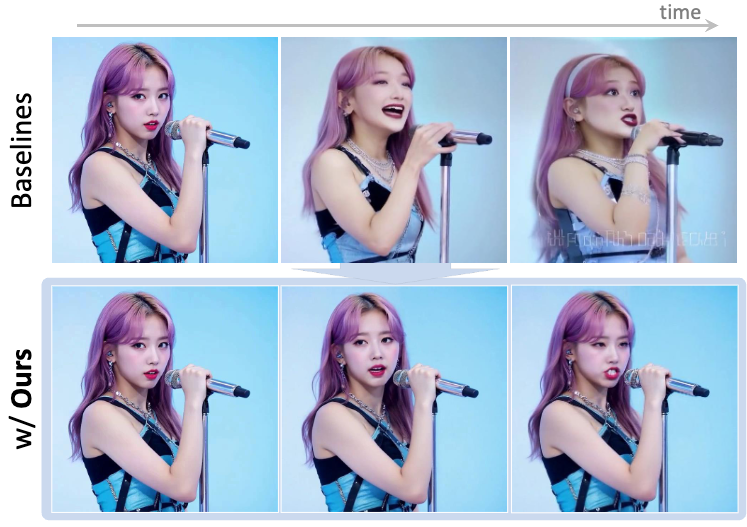
Antoni Bigata, Rodrigo Mira, Stella Bounareli, Michał Stypułkowski, Konstantinos Vougioukas, Stavros Petridis, Maja Pantic
Published in arXiv, 2025
[paper] [project page] [code] [bib]
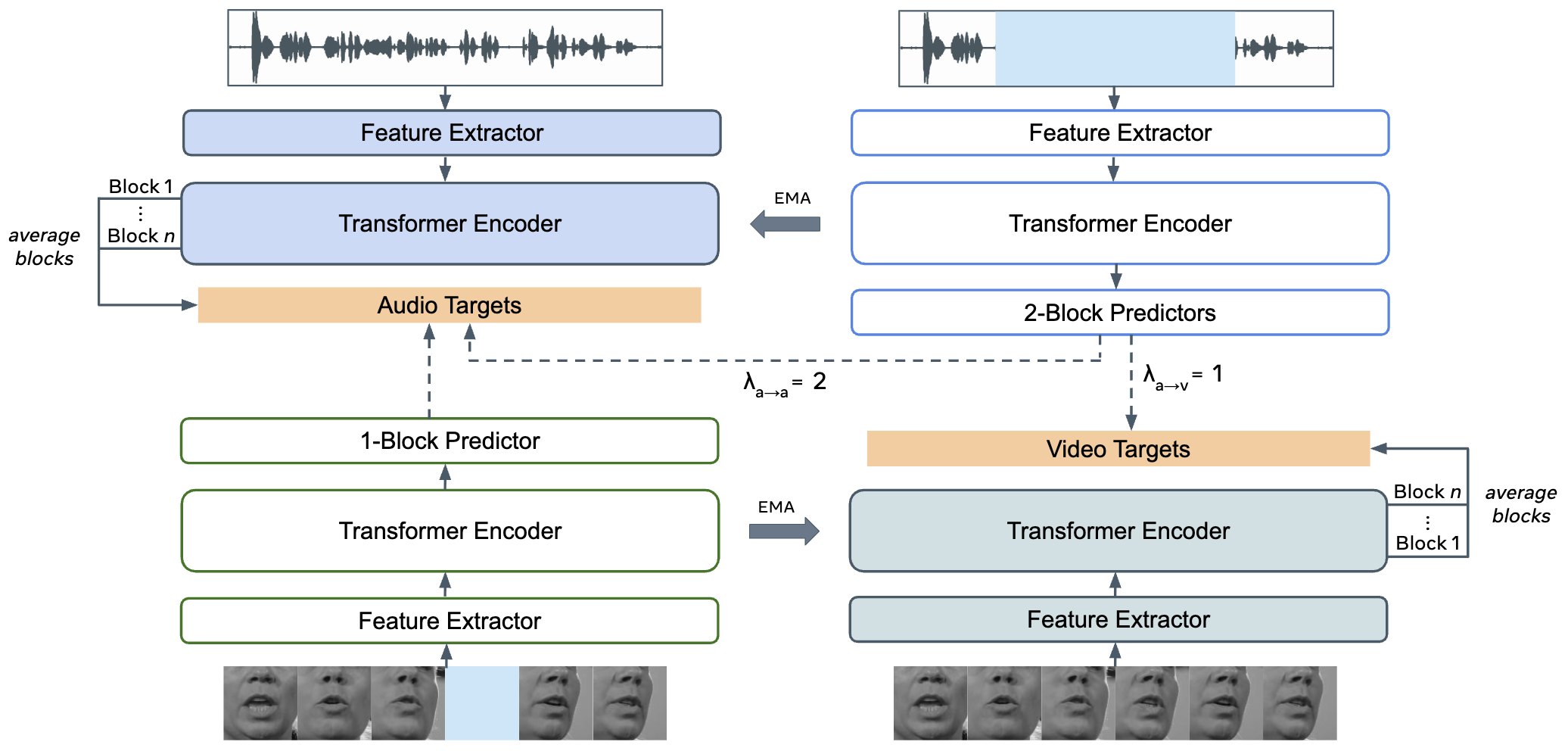
Junyoung Seo, Rodrigo Mira, Alexandros Haliassos, Stella Bounareli, Honglie Chen, Linh Tran, Seungryong Kim, Zoe Landgraf, Jie Shen
Published in arXiv, 2025
[paper] [project page] [code] [bib]
Alexandros Haliassos, Rodrigo Mira, Stavros Petridis
Published in ICLR, 2026
Published:
Short talk where I introduced our new video-to-speech model and showed its performance using an interactive demo.
[recording] [slides]
Published:
Short talk where I presented our new end-to-end video-to-speech model (later published in IEEE Trans. on Cybernetics).
[recording (presentation at 42:23, questions at 57:38)] [slides] [short paper]
Published:
Short presentation where I talked about past, current and future trends in self-supervised learning, including BYOL.
[slides]
Published:
I presented a summary of my PhD’s research contributions to the president of Portugal, Marcelo Rebelo de Sousa, as well as many other attendees at Imperial College London.
[poster] [article]
Published:
Short talk where I presented our new scalable video-to-speech model (later published in Interspeech 2022).
[recording (presentation at 1:34:10)] [slides] [short paper]
Published:
Short talk where I presented our new scalable video-to-speech model (later published in Interspeech 2022).
[recording] [slides]
Published:
Oral presentation about our new scalable video-to-speech model (SVTS).
[recording] [slides] [paper]
Published:
Short presentation where I talked about neural vocoders, and how they are moving away from GANs and towards diffusion models.
[slides]
Published:
Short presentation where I talked about EnCodec, a new neural codec that achieves state-of-the-art results on clean/noisy speech and music at 24/48 kHz (mono and stereo). It also has open-source code and outperforms Google’s approach - LyraV2.
[slides]
Published:
Short talks where I presented my new papers on audio-visual self-supervised learning (RAVEn, published in ICLR 2023) and audio-visual speech enhancement (LA-VocE, published in ICASSP 2023).
[RAVEn recording] [LA-VocE recording] [RAVEn slides] [LA-VocE slides] [RAVEn short paper] [LA-VocE short paper]